Architecture
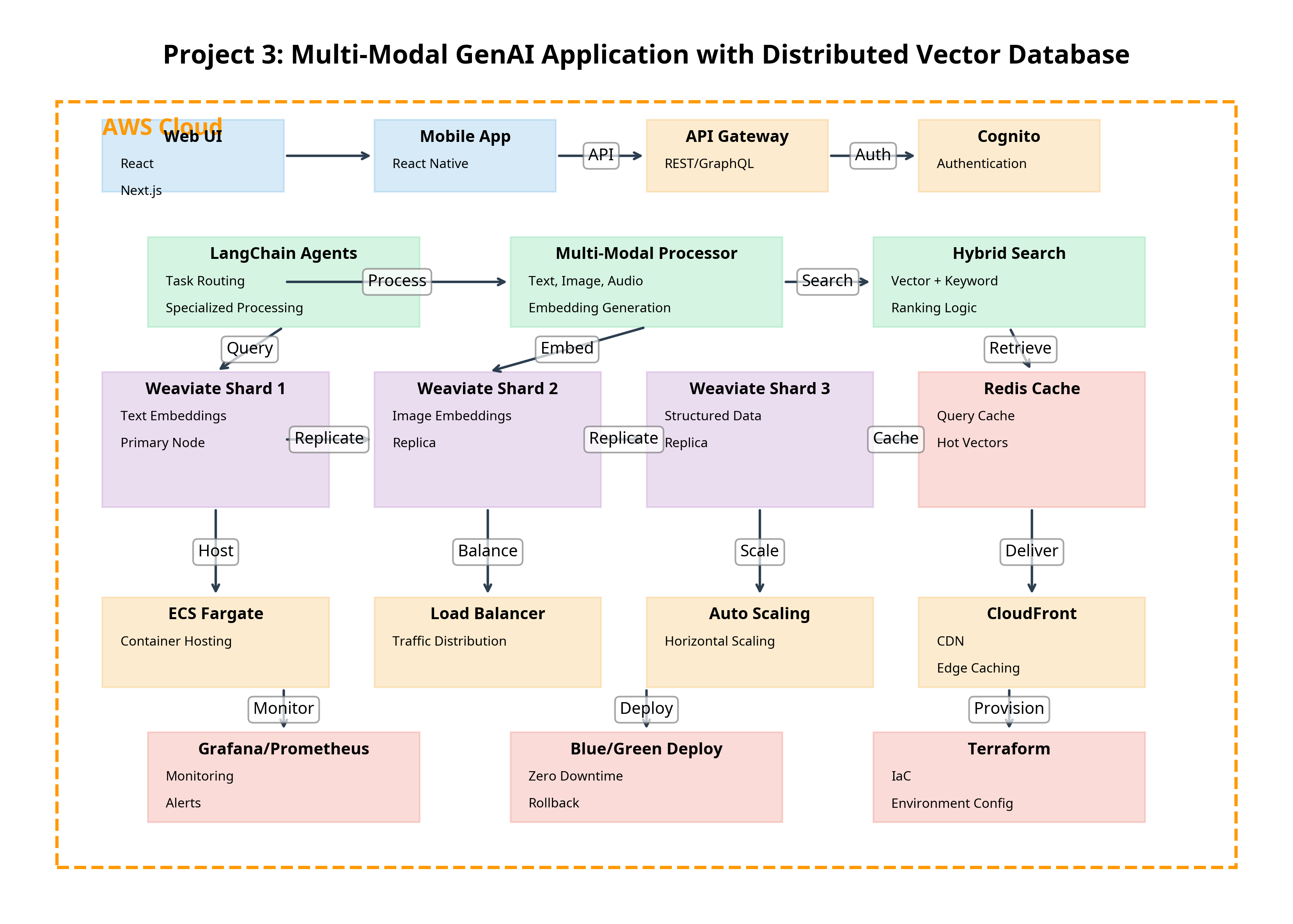
Architecture Components
- Weaviate Cluster: Distributed vector database with sharding
- Redis Cache: Query caching for performance
- FastAPI Service: API endpoints and orchestration
- LangChain Agents: Task routing and specialized processing
- ECS Fargate: Containerized deployment
- Application Load Balancer: Traffic distribution
- S3: Object storage for media files
- CloudFront: CDN for media delivery
- Prometheus/Grafana: Monitoring and visualization
- Terraform: Infrastructure as Code