Architecture
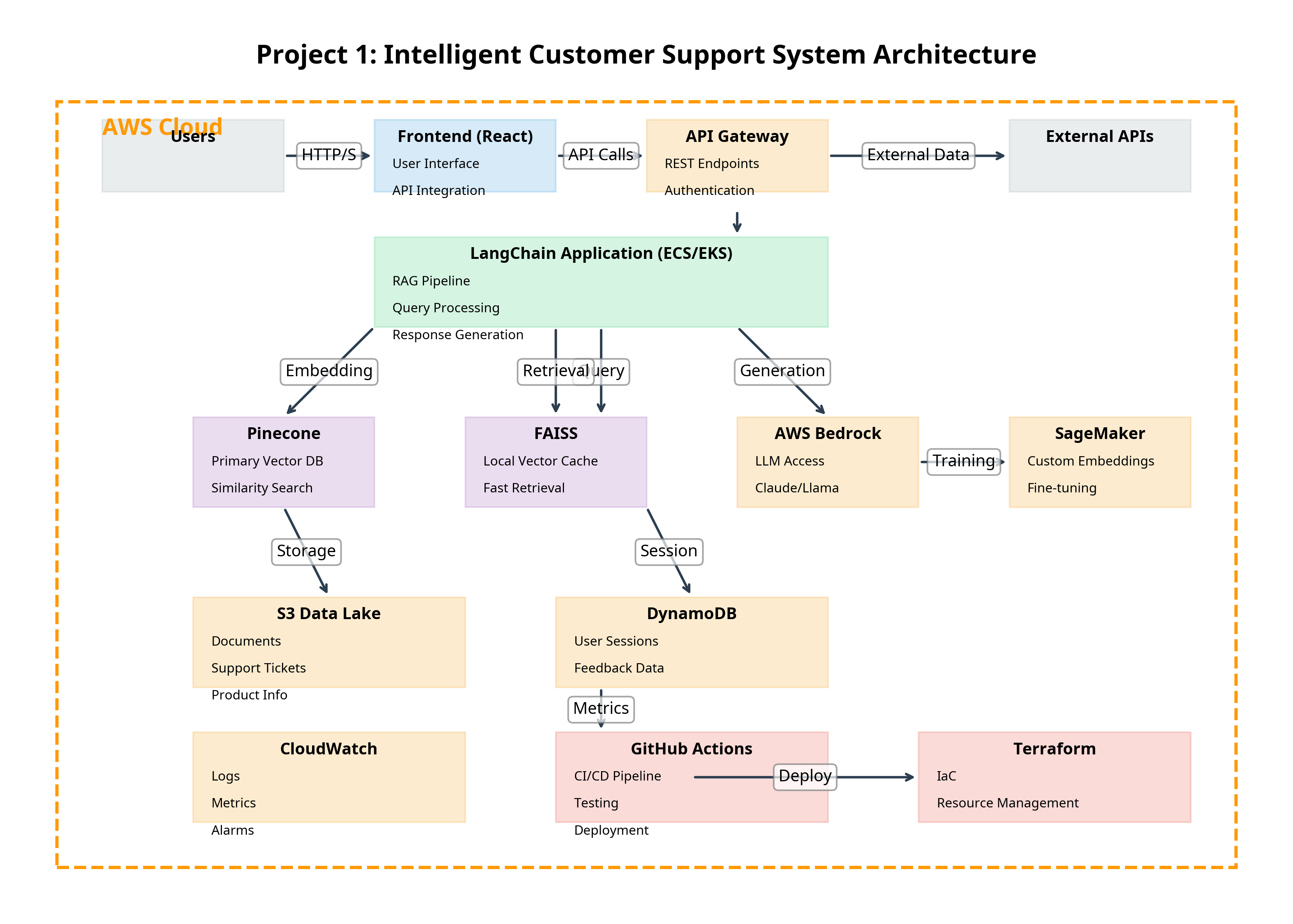
Architecture Components
- Frontend: React-based user interface
- API Gateway: REST endpoints and authentication
- LangChain Application: Core RAG pipeline running on ECS/EKS
- Vector Databases: Pinecone for primary storage, FAISS for local caching
- AWS Bedrock: Access to Claude/Llama models
- SageMaker: Custom embeddings and fine-tuning
- S3 Data Lake: Document storage
- DynamoDB: Session and feedback data
- CloudWatch: Monitoring and alerting
- CI/CD: GitHub Actions and Terraform